
URI 相关知识
0x01 概述
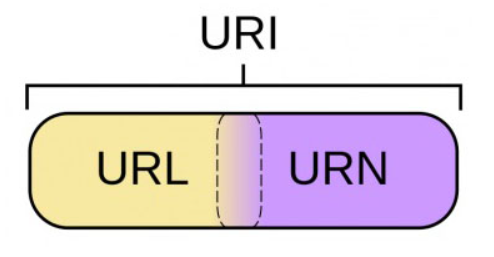
URI
URI,全称是
Uniform Resource Identifiers,即统一资源标识符。 用于在互联网上标识一个唯一的资源,这里的“资源”表示的是 web 上每一种可用的资源(抽象或者物理资源),如 HTML 文档、图像、视频片段、程序等。
URL
URL,全称是
Universal Resource Locator,即统一资源定位符。用于指示资源的位置以及用于访问它的协议。
URN
URN,全称是
Universal Resource Name,即统一资源名称。
- URI 属于 URL 更高层次的抽象,一种字符串文本标准。
- URI 表示请求服务器的路径,定义这么一个资源。而 URL 是一种具体的 URI,同时说明要如何访问这个资源(访问协议)。
URL 的组成
完整的 URI,由四个主要的部分构成:协议、主机、端口、路径
<scheme>://<authority><path>?<query>
<scheme>://<host>:<port>/<path>?<query>
<scheme>://<user>:<password>@<host>:<port>/<path>;<params>?<query>#<frag>
scheme 表示协议,比如http,ftp 等等,详细介绍可以参考 rfc2396#section-3.1。
authority,用:// 来和scheme 区分。从字面意思看就是“认证”,“鉴权”的意思,引用 rfc2396#secion-3.2 的一句话:This authority component is typically defined by an Internet-based server or a scheme-specific registry of naming authorities.
这个“认证”部分,由一个基于 Internet 的服务器定义或者由命名机关注册登记(和具体的协议有关)。
而常见的
authority 则是:“由基于 Internet 的服务器定义”,其格式如下:
<userinfo>@<host>:<port>
**userinfo** 这个域用于填写一些用户相关的信息,比如可能会填写 “user:password”,当然这是不被建议的。
**<host>:<port>** 则是被熟知的服务器地址了,host 可以是域名,也可以是对应的 IP 地址,port 表示端口,这是一个可选项,如果不填写,会使用默认端口(也是和协议相关,比如http 协议默认端口是 80)。
**path**,在scheme 和authority 确定下来的情况下标识资源,path 由几个段组成,每个段用/ 来分隔。注意,path 不等同于文件系统定义的路径。
**query**,查询串(或者说参数串),用? 和path 区分开来,其具体的含义由这个具体资源来定义。
如
URL(统一资源定位符)
http://localhost:8080/struts2/index.jsp
- 协议:http://
- 主机:localhost
- 端口:8080
- URI:/struts2/index.jsp
URI(统一资源标识符)
URL 保留字符及编码
从上面的描述里看,URI 的这 4 个组件,由特定的分隔符来分离,这些分隔符各自有着特殊含义,而如果这些分隔符出现在某个组件内,比如
path 是/a/b?c.html,那么从 URI 整体角度来看的话,c.html 会被当做是query,这样就破坏了path 原本的含义,因此 URI 引入了保留字符集,这些字符有着特殊的目的,如果它们被用于描述资源(而不是作为分隔符出现),那么必须对它们转义。那么什么情况下需要对一个字符转义呢,引用 rfc2395#section-2.2 的一句话:
In general, a character is reserved if the semantics of the URI changes if the character is replaced with its escaped US-ASCII encoding.
即如果转义前后这个字符会影响到整个 URI 的意义,则它必须被转义。
US-ASCII 字符集中没有对应的可打印字符:Url 中只允许使用可打印字符。US-ASCII 码中的 10-7F 字节全都表示控制字符,这些字符都不能直接出现在 Url 中。同时,对于 80-FF 字节(ISO-8859-1),由于已经超出了 US-ACII 定义的字节范围,因此也不可以放在 Url 中。
保留字符:Url 可以划分成若干个组件,协议、主机、路径等。有一些字符(:/?#[]@)是用作分隔不同组件的。例如 : 冒号用于分隔协议和主机,/ 用于分隔主机和路径,? 用于分隔路径和查询参数,等等。还有一些字符(!$&'()*+,;=)用于在每个组件中起到分隔作用的,如 = 用于表示查询参数中的键值对,& 符号用于分隔查询多个键值对。当组件中的普通数据包含这些特殊字符时,需要对其进行编码。
由于 URI 由多个组件构成,一个字符不转义,可能会对其中一个组件会造成影响,但对另一个组件没有影响,所以“保留字符集”是由具体的 URI 组件来规定的。
对
path 部分而言,保留字符集是(参考自 rfc2396):reserved = "/" | "?" | ";" | "="对
query 部分而言,保留字符集是(参考自 rfc2396):reserved = ";" | "/" | "?" | ":" | "@" | "&" | "=" | "+" | "," | "$"HTML URL 编码参考手册
保留字符就是那些在 URL 中具有特定意义的字符。
不安全字符 - rfc1738 2.2 节是指那些在 URL 中没有特殊含义,但在 URL 所在的上下文中可能具有特殊意义的字符。不加处理地存在在 URI 里,会破坏 URI 的语义完整性,对于这类字符,如果要出现在 URI 里,那么也得进行转义。
! * ' ( ) + $ ,
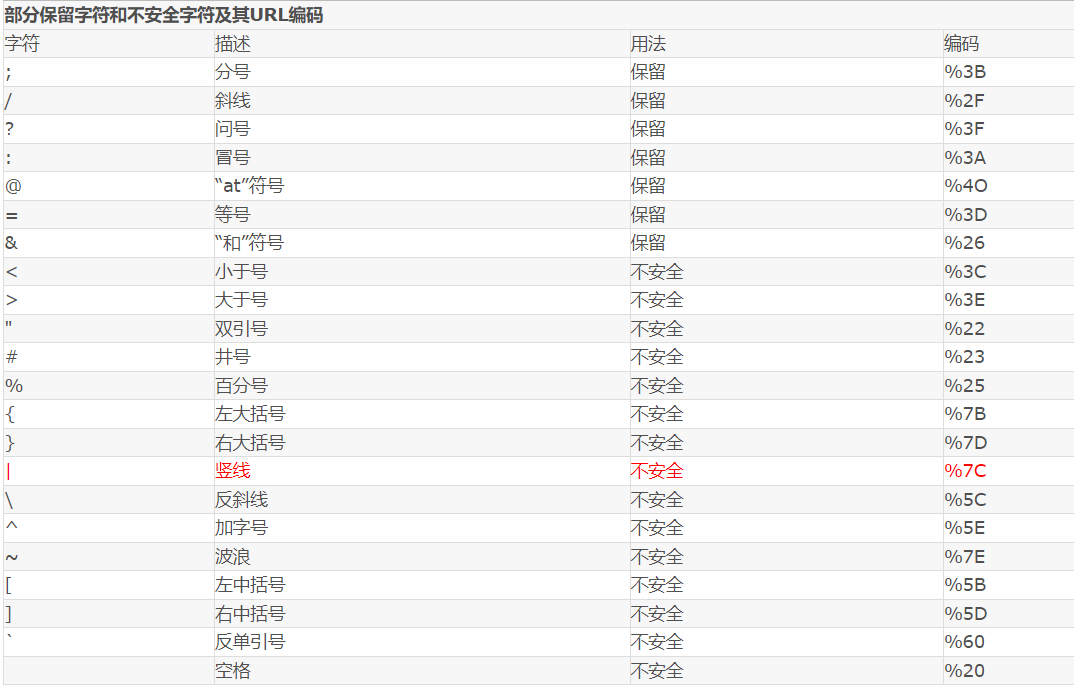
RFC3986 中指定了以下字符为保留字符:! * ' ( ) ; : @ & = + $ , / ? # [ ]
不安全字符:还有一些字符,当他们直接放在 Url 中的时候,可能会引起解析程序的歧义。这些字符被视为不安全字符,原因有很多。
- 空格:Url 在传输的过程,或者用户在排版的过程,或者文本处理程序在处理 Url 的过程,都有可能引入无关紧要的空格,或者将那些有意义的空格给去掉。
- 引号以及
<>:引号和尖括号通常用于在普通文本中起到分隔 Url 的作用 -
#:通常用于表示书签或者锚点 -
%:百分号本身用作对不安全字符进行编码时使用的特殊字符,因此本身需要编码 -
{}|^[]~`:某一些网关或者传输代理会篡改这些字符
需要注意的是,对于 Url 中的合法字符,编码和不编码是等价的,但是对于上面提到的这些字符,如果不经过编码,那么它们有可能会造成 Url 语义的不同。因此对于 Url 而言,只有普通英文字符和数字,特殊字符 $-_.+!*'() 还有保留字符,才能出现在未经编码的 Url 之中。其他字符均需要经过编码之后才能出现在 Url 中。
但是由于历史原因,目前尚存在一些不标准的编码实现。例如,虽然 RFC3986 文档规定,对于波浪符号 ~,不需要进行 Url 编码,但是还是有很多老的网关或者传输代理会进行编码。
如何对 Url 中的非法字符进行编码
Url 编码通常也被称为百分号编码(Url Encoding,also known as percent-encoding),是因为它的编码方式非常简单,使用 % 百分号加上两位的字符——0123456789ABCDEF——代表一个字节的十六进制形式。Url 编码默认使用的字符集是 US-ASCII。
对于非 ASCII 字符,需要使用 ASCII 字符集的超集进行编码得到相应的字节,然后对每个字节执行百分号编码。
对于 Unicode 字符,RFC 文档建议使用 utf-8 对其进行编码得到相应的字节,然后对每个字节执行百分号编码。如"中文"使用 UTF-8 字符集得到的字节为 0xE4 0xB8 0xAD 0xE6 0x96 0x87,经过 Url 编码之后得到 %E4%B8%AD%E6%96%87 。
字符是可由八位字节数(octet)来表示的,八位字节数可用十六进制来表示它的值。如字符
< 的八位字节数十六进制值是 3C。在 URL 中,字符的编码方式为:% 加上字符的两个十六进制数值。a 在 US-ASCII 码中对应的字节是 0x61,那么 Url 编码之后得到的就是
%61“田” 的 UTF-8 编码十六进制值是 E7 94 B0,这时 “田” 的 URL 编码为
%E7%94%B0如果某个字节对应着 ASCII 字符集中的某个非保留字符,则此字节无需使用百分号表示。 例如 "Url 编码",使用 UTF-8 编码得到的字节是
0x55 0x72 0x6C 0xE7 0xBC 0x96 0xE7 0xA0 0x81,由于前三个字节对应着 ASCII 中的非保留字符"Url",因此这三个字节可以用非保留字符"Url"表示。最终的 Url 编码可以简化成Url%E7%BC%96%E7%A0%81,当然,如果你用%55%72%6C%E7%BC%96%E7%A0%81 也是可以的。
# 的含义-
# 代表网页中的一个位置。其右面的字符,就是该位置的标识符。比如,http://www.example.com/index.html#print 就代表网页index.html 的print 位置。浏览器读取这个 URL 后,会自动将 print 位置滚动至可视区域。 - 为网页位置指定标识符,有两个方法。一是使用锚点,比如
<a name="print"></a>,二是使用 id 属性,比如<div id="print">。
-
HTTP 请求不包括
#,# 是用来指导浏览器动作的,对服务器端完全无用,所以# 后的字符都不会被发送到服务器端。比如,访问下面的网址,http://www.example.com/index.html#print,浏览器实际发出的请求是这样的
GET /index.html HTTP/1.1 Host: www.example.com改变
# 不触发网页重载改变
# 会改变浏览器的访问历史
window.location.hash 读取# 值
window.location.hash ** 这个属性可读可写。读取时,可以用来判断网页状态是否改变;写入时,则会在不重载网页的前提下,创造一条访问历史记录。**默认情况下,Google 的网络爬虫会忽视 URL 的
# 部分。但是,Google 还规定,如果你希望 Ajax 生成的内容被浏览引擎读取,那么 URL 中可以使用
#! ,Google 会自动将其后面的内容转成查询字符串_escaped_fragment_ 的值。比如,Google 发现新版 twitter 的 URL:http://twitter.com/#!/username 就会自动抓取另一个 URL:http://twitter.com/?escaped_fragment=/username 。
通过这种机制,Google 就可以索引动态的 Ajax 内容。
?1)连接作用:比如
http://www.xxx.com/Show.asp?id=77&nameid=2905210001&page=1
2)清除缓存:比如
http://www.xxxxx.com/index.html
http://www.xxxxx.com/index.html?test123123
两个 url 打开的页面一样,但是后面这个有问号,说明不调用缓存的内容,而认为是一个新地址,重新读取。
& 参数间隔符
0x02 nginx 的 URI 转义机制
nginx (以 1.13.8 版本为准)提供了一个名为 ngx_escape_uri 的函数,函数原型如下:
uintptr_t ngx_escape_uri(u_char *dst, u_char *src, size_t size,
ngx_uint_t type);
第三个参数 type,可以接受这些值:
#define NGX_ESCAPE_URI 0
#define NGX_ESCAPE_ARGS 1
#define NGX_ESCAPE_URI_COMPONENT 2
#define NGX_ESCAPE_HTML 3
#define NGX_ESCAPE_REFRESH 4
#define NGX_ESCAPE_MEMCACHED 5
#define NGX_ESCAPE_MAIL_AUTH 6
我们只关心其中的 NGX_ESCAPE_URI ,NGX_ESCAPE_ARGS ,NGX_ESCAPE_URI_COMPONENT ,根据 nginx 官方所提供的 nginx 模块和核心 API 介绍,这三个宏的含义如下:
TypeDefinitionNGX_ESCAPE_URIEscape a standard URINGX_ESCAPE_ARGSEscape query argumentsNGX_ESCAPE_URI_COMPONENTEscape the URI after the domain
对应地,ngx_escape_uri 这个函数,内置了几个相关的 bitmap,区别就是在于各自的转义字符集,具体可以查阅 nginx 的源码(src/core/ngx_string.c)。
其中针对整个 URI 的转义处理,ngx_escape_uri 会把
" ", "#", "%", "?" 以及%00-%1F 和%7F-%FF 的字符转义;- 针对
query 的转义,会把" ", "#", "%", "&", "+", "?" 以及%00-%1F 和%7F-%FF 的字符转义; - 针对
path +query(称之为 the URI after the domain)的转义,会把除英文字母,数字,以及"-", ".", "_", "~" 这些以外的字符全部转义。
可以看到,NGX_ESCAPE_URI 和 <span>NGX_ESCAPE_ARGS</span> 没有处理不安全字符,前者站在处理整个的 URI 的角度上编码,后者站在处理 query 的角度上编码;
而 NGX_ESCAPE_URI_COMPONENT ,处理角度不是整个 URI,而是 domain 之后的 URI 组件,它兼顾 path 和 query 的保留字符集,更加严格,遵守了 rfc3986#section-2.2 的规范。
这里顺便提一下 ngx_proxy 模块对应的 URI 转义处理,在构造向上游发送的请求行时,ngx_proxy 模块针对 proxy_pass 指令做出了不同的处理:
如果指定的 URI 包含了变量,将解析变量,然后直接将解析后的 URI 发送到上游;
如果 URI 不含变量,且没有指定
path 部分,将使用客户端发来的path 部分拼接到 URI 中,然后发送到上游;如果 URI 不含变量,且指定了
path,这里的处理比较特殊,nginx 会把解码过的,由客户端发来的 URI 里的path 部分(去掉和当前location 的公共前缀),进行编码(按NGX_ESCAPE_URI 来操作),和proxy_pass 指令指定 的path 拼接,发送到上游,比如这样的配置:location /foo { proxy_pass http://127.0.0.1:8082/bar; }如果客户端发来的 URI 里
path 是/foo/%5B-%5D,最终上游的 URIpath 会是/bar/[-]。
因此我们在做 nginx conf 配置的时候,也需要小心考虑 URI 编码的问题。
0x03 ngx_lua 的 URI 转义机制
ngx_lua 提供的 ngx.escape_uri 函数,和 nginx 核心的转义机制也有一些差异(基于 ngx_lua v0.10.11),体现在对保留字符的处理上,ngx.escape_uri 底层使用的 ngx_http_lua_escape_uri,结构和 ngx_escape_uri 一致,而对应的 bitmap 不同。
对于整个 URI 的转义处理,在
ngx_escape_uri 的基础上,对'"', '&', '+', '/', ':', ';', '<', '=', '>', '[', '\', ']', '^', '_', '{' , '}'进行转义;对于
query 的处理,这里去掉了& 的转义;对于
path +query 的处理,去掉了对"'", "*", ")", "(", "!" 的转义。目前
ngx.escape_uri 使用的是NGX_ESCAPE_URI_COMPONENT,从 PR 提交的信息来看,目前ngx.escape_uri 的行为和 Chrome JS 实现的encodeURIComponent 一致。
另外,ngx_lua 对 URI 的解码操作,除了它把 + 解码为空格以外,其他和 nginx 相同。
0x04 Tomcat 与 Nginx 对 url 中的特殊字符处理
Orange 大佬在 black hat 发的一篇关于路径穿越的议题,PDF:https://i.blackhat.com/us-18/Wed-August-8/us-18-Orange-Tsai-Breaking-Parser-Logic-Take-Your-Path-Normalization-Off-And-Pop-0days-Out-2.pdf
nginx 配置应该形如是这样:
server {
listen 80;
server_name www.123.com;
location /examples/ {
proxy_pass http://127.0.0.1:8080/examples/;
index index.html index.htm index.jsp;
}
}
访问 http://127.0.0.1:8080/examples/…;/manager/html 的时候,更据第 5 行的 location 会反向代理到 tomcat 中,传给 tomcat 的为:http://127.0.0.1:8080/examples/…;/manager/html
对于 url 含有 ’;’ ,tomcat 经过 postParseRequest() 函数处理,会删掉 ’;’ 到 ’/‘ 之间的字符,比如 ’/…;123/’ 会变为 ’…/’。然后经过 normalize() 处理会变为:http://127.0.0.1:8080/manager/html
对于一开始那个为什么直接用 http://127.0.0.1:8080/…;/examples/websocket/index.xhtml 会报 400 错误,原因就是在 normalize() 函数中进行了判断,如果 normalize 之后 …/ 是 url 开头的话 ,会返回 400。
tomcat 对 url 特殊字符的处理主要是三个步骤对于三个函数:
- 先是
postParseRequest() 函数对’;’ 分号进行处理。比如把’/123;456/’ 替换为’/123/’。 - 然后是调用
req.getURLDecoder().convert() 函数对 URL 中进行了 URL 编码的字符进行解码,其中如果解码之后的结果是’/’ ,也就是输入的 URL 含有’%2f’ 就会返回 400。 - 接着是调用
normalize() 函数对 URL 进行规范化,比如处理’/…/’ ,’/./’,’\’,’//’。 - 另外 URL 中如果含有空字符串,则会返回 400。如果规范化后的 url 是以
’…/' 开头的,也会返回 400。

0x05 Javascript 中的 escape, encodeURI 和 encodeURIComponent 的区别
Javascript 中提供了 3 对函数用来对 Url 编码以得到合法的 Url,它们分别是 escape / unescape, encodeURI / decodeURI 和 encodeURIComponent / decodeURIComponent。
这三个编码的函数——escape,encodeURI,encodeURIComponent——都是用于将不安全不合法的 Url 字符转换为合法的 Url 字符表示,它们有以下几个不同点。
安全字符不同: 下面列出了这三个函数的安全字符(即函数不会对这些字符进行编码)
- escape(69 个):
*/@+-._0-9a-zA-Z - encodeURI(82 个):
!#$&'()*+,/:;=?@-._~0-9a-zA-Z - encodeURIComponent(71 个):
!'()*-._~0-9a-zA-Z
兼容性不同: escape 函数是从 Javascript 1.0 的时候就存在了,其他两个函数是在 Javascript 1.5 才引入的。但是由于 Javascript 1.5 已经非常普及了,所以实际上使用 encodeURI 和 encodeURIComponent 并不会有什么兼容性问题。
对 Unicode 字符的编码方式不同: 这三个函数对于 ASCII 字符的编码方式相同,均是使用百分号 + 两位十六进制字符来表示。但是对于 Unicode 字符,escape 的编码方式是 %uxxxx,其中的 xxxx 是用来表示 unicode 字符的 4 位十六进制字符。这种方式已经被 W3C 废弃了。但是在 ECMA-262 标准中仍然保留着 escape 的这种编码语法。encodeURI 和 encodeURIComponent 则使用 UTF-8 对非 ASCII 字符进行编码,然后再进行百分号编码。这是 RFC 推荐的。因此建议尽可能的使用这两个函数替代 escape 进行编码。
表单提交
当 Html 的表单被提交时,每个表单域都会被 Url 编码之后才在被发送。由于历史的原因,表单使用的 Url 编码实现并不符合最新的标准。例如对于空格使用的编码并不是 %20,而是 + 号,如果表单使用的是 Post 方法提交的,我们可以在 HTTP 头中看到有一个 Content-Type 的 header,值为 application/x-www-form-urlencoded。大部分应用程序均能处理这种非标准实现的 Url 编码,但是在客户端 Javascript 中,并没有一个函数能够将 + 号解码成空格,只能自己写转换函数。还有,对于非 ASCII 字符,使用的编码字符集取决于当前文档使用的字符集。例如我们在 Html 头部加上 charset 属性。
<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />
常用 bypass 技巧
@ 绕过 用了浏览器的特性,@ 请求的实际是@ 后面的内容。http://baidu.com@google.com/ 实际访问的是 google
原理如下:利用解析 URL 时的规则问题。
在 2017 年的 Blackhat 大会上,Orange Thai 在 blackhat 中发表的演讲《A New Era of SSRF - Exploiting URL Parser in Trending Programming Languages! 》
http://baidu.com@www.baidu.com/ 和 http://www.baidu.com/ 请求时是相同的 可以通过 curl 命令进行测试 * curl http://baidu.com@www.baidu.com * curl http://www.baidu.com 返回的内容是一样的 * 但是 `curl http://baidu.com` 和 `curl http://www.baidu.com` 返回的内容是不一样的
? 问号绕过 可以使用页面Referer 作为后缀:https://www.dddd.me/redirect.php?url=https://www.evil.com?www.dddd.me
# 锚点绕过 利用# 会被浏览器解释成 HTML 中的锚点http://127.0.0.1/#baidu.com
xip.io 绕过:http://www.baidu.com.127.0.0.1.xip.io/指向任意 ip 的域名:xip.io xip.io 是一个开源泛域名服务。你可以无需配置,将自定义的任何域名解析到指定的 IP 地址。假设你的 IP 地址是 10.0.0.1,你只需使用 ”前缀域名+IP 地址+xip.io“ 即可完成相应自定义域名解析。 比如你需要测试一个 web 服务器,但是你还没申请域名,本地测试大多的办法是改 host 大法,host 映射域名到一个 IP 主机地址,现在有了 xip 就不用改 host 了。 ========== 如 192.168.201.152 www.mob.com http://域名+地址+xip.io,将解析到对应地址。 ========== http://10.0.0.1.xip.io = 10.0.0.1 # 解析到 10.0.0.1 www.10.0.0.1.xip.io = 10.0.0.1 # www 子域解析到 10.0.0.1 http://mysite.10.0.0.1.xip.io = 10.0.0.1 foo.http://bar.10.0.0.1.xip.io = 10.0.0.1 如果你想使用自己的域名来实现一个类似 xip.io 同样功能也是很容易的。你只需部署一个 xip.name 的开源软件就可以简单实现了! xip.name 使用 Golang 开发的一个支持通配符的 DNS 服务器,它的使用上和 xip.io 无异。 ========== https://github.com/peterhellberg/xip.name 10.0.0.1.xip.name resolves to 10.0.0.1 www.10.0.0.2.xip.name resolves to 10.0.0.2 # www 子域解析到 10.0.0.2 foo.10.0.0.3.xip.name resolves to 10.0.0.3 # foo 子域解析到 10.0.0.2 bar.baz.10.0.0.4.xip.name resolves to 10.0.0.4 # bar.baz 子域解析到 10.0.0.4 ========== 短网址或者短网址 + xip.io 127.0.0.1–>http://weibo.ws/fBkSBb 127.0.0.1.xip.io–>http://weibo.ws/rujDdn
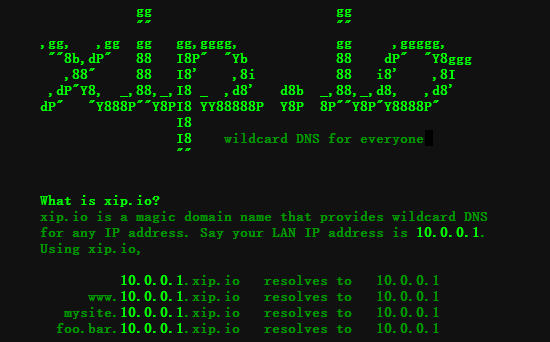
【或者使用它】https://sslip.io/
\ 反斜杠绕过:https://maxx.com/jump.html?url=https:/\baidu.com
IP 绕过:把目标的 URL 修改成 IP 地址(如何过滤了. 号请使用十进制符号的 IPv4 地址),这样也有可能绕过 waf 的拦截(IP 地址转换:http://www.geektools.com/geektools-cgi/ipconv.cgi)
HPP 参数污染绕过:构造相同的参数两次?next=whitelisted.com&next=google.comTry
target.com/?redirect_url=.uk (or[any_param]=.uk). If it redirects to target.com.uk, then it’s vulnerable!target.com.uk andtarget.com are different domains.
编码绕过:尝试使用双 url (把% 本身编码成%25)和三 url 编码(%252522)的有效负载版本符号 \ 进行 url 编码一次是 %5c,二次编码把 % 本身编码成 %25 再和后边拼成 %255c ========== - 若 URL 解码器有缺陷,只不断重复“从前边开始解析”这个步骤,就会把这个先变回 %5c,再变成 /,出现循环解析。当然这是错误的。 - 正确的只应该解一步变成%5c。 ========== . = %252e / = %252f \ = %255cUse
/U+e280 RIGHT-TO-LEFT OVERRIDE:https://whitelisted.com@%E2%80%AE@moc.elgoogThe unicode character
U+202E changes all subsequent text to be right-to-leftE.g.:https://hackerone.com/reports/299403
根据报告还能在
@ 后面添加某些字符,通过# 形成 url。If you put symbols like " / $ etc after @ , it forms a malformed urls. For eg, https://google.com@"twitter.com https://google.com@'twitter.com https://google.com@/twitter.com Further, these symbols can be made as domains by putting # Just after the above symbols https://google.com@'#twitter.com
特殊字符绕过:尝试使用不同的符号重定向到 IP 地址(而不是域):IPv6,IPv4(十进制,十六进制或八进制)源 IP:192.168.0.1 (1)、 8 进制格式:0300.0250.0.1 (2)、16 进制格式:0xC0.0xA8.0.1 (3)、10 进制整数格式:3232235521 (4)、16 进制整数格式:0xC0A80001
利用 XSS 漏洞绕过:对于 XSS 尝试将alert(1) 替换为prompt(1) & confirm(1),尝试重定向它的子域上面target.com/?redirect_url=xss.target.com
文件后缀绕过:如果选中扩展名为.jpg 图片跳转可使用这种方式绕过image_url={payload}/.jpg缺少协议绕过
https://maxx.com/redirect.php?url=//www.evil.com多斜线
”/“ 前缀绕过 https://maxx.com/redirect.php?url=///www.evil.com https://maxx.com/redirect.php?url=////www.evil.com在有些情况下 XSS 只能造成跳转的危害
<meta content="1;url=http://www.baidu.com" http-equiv="refresh">如果
. 被加入黑名单, 可以尝试一下%E3%80%82 (解码后是中文的 。)。用 url 双编码,比如
https://baidu%252ecom
基础元字符字典 Bypass-Payload:List
① ② ③ ④ ⑤ ⑥ ⑦ ⑧ ⑨ ⑩ ⑪ ⑫ ⑬ ⑭ ⑮ ⑯ ⑰ ⑱ ⑲ ⑳
⑴ ⑵ ⑶ ⑷ ⑸ ⑹ ⑺ ⑻ ⑼ ⑽ ⑾ ⑿ ⒀ ⒁ ⒂ ⒃ ⒄ ⒅ ⒆ ⒇
⒈ ⒉ ⒊ ⒋ ⒌ ⒍ ⒎ ⒏ ⒐ ⒑ ⒒ ⒓ ⒔ ⒕ ⒖ ⒗ ⒘ ⒙ ⒚ ⒛
⒜ ⒝ ⒞ ⒟ ⒠ ⒡ ⒢ ⒣ ⒤ ⒥ ⒦ ⒧ ⒨ ⒩ ⒪ ⒫ ⒬ ⒭ ⒮ ⒯ ⒰ ⒱ ⒲ ⒳ ⒴ ⒵
Ⓐ Ⓑ Ⓒ Ⓓ Ⓔ Ⓕ Ⓖ Ⓗ Ⓘ Ⓙ Ⓚ Ⓛ Ⓜ Ⓝ Ⓞ Ⓟ Ⓠ Ⓡ Ⓢ Ⓣ Ⓤ Ⓥ Ⓦ Ⓧ Ⓨ Ⓩ
ⓐ ⓑ ⓒ ⓓ ⓔ ⓕ ⓖ ⓗ ⓘ ⓙ ⓚ ⓛ ⓜ ⓝ ⓞ ⓟ ⓠ ⓡ ⓢ ⓣ ⓤ ⓥ ⓦ ⓧ ⓨ ⓩ
⓪ ⓫ ⓬ ⓭ ⓮ ⓯ ⓰ ⓱ ⓲ ⓳ ⓴ ⓵ ⓶ ⓷ ⓸ ⓹ ⓺ ⓻ ⓼ ⓽ ⓾ ⓿
- ~ ? %
由于 DNS 服务器的解析是由英文代码所构成,所以浏览器会在访问资源前会对域名进行解码,而多个 ascii 字符会被解码成同一个英文字母,我们可以编写简单的 JavaScript 脚本进行 fuzz。实战钓鱼之 url 魔改 (qq.com)
for (let i=0;i<=65535;i++)
{
var a = 'https://'+ String.fromCharCode(i) +'kun.org';
try{
let url = new URL(a);
if (url.hostname && url.hostname == "ikun.org")
{
console.log(i,String.fromCharCode(i));
}
}catch{
// console.log("error");
}
}
通过脚本我们找出域名所对应的 ascii 字符,比如英文字母 i 同时对应:
I i ᴵ ᵢ ⁱ ℐ ℑ ℹ ⅈ Ⅰ ⅰ Ⓘ ⓘ I i
url 进一步伪造成了
https://www.bing.com&action=login@ℐⓀⓊⁿ.ºʳℊ
# 结合上面的进制编码混淆,假如 ikun.org 的 ip 地址为 127.0.0.1
- 二进制编码:01111111 00000000 00000000 00000001
- 十进制编码:2130706433
-->
https://www.bing.com&action=login@2130706433
--> 在通过添加对服务端解析没用的锚点,
https://www.bing.com&action=login@2130706433#3.docx